Motivation
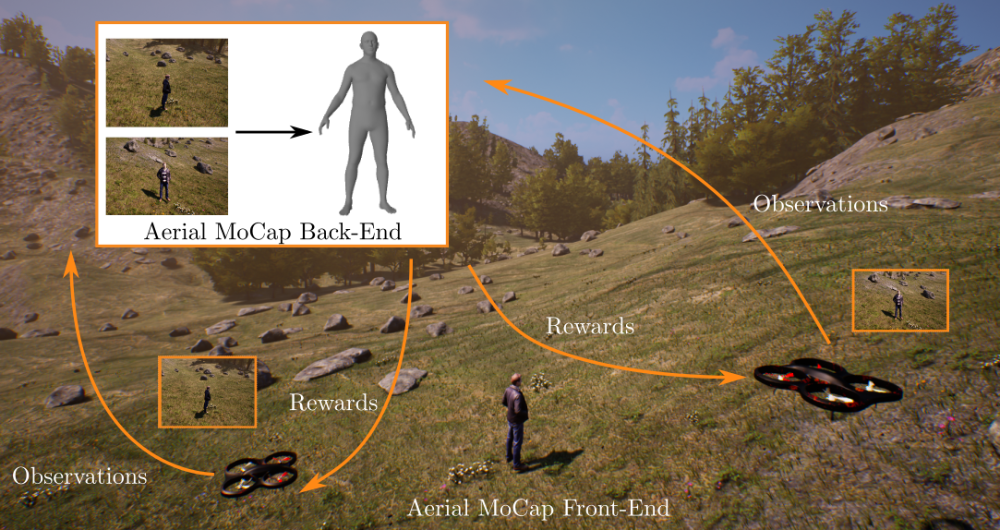
Realizing an aerial motion capture (MoCap) system for humans or animals involves several challenges. The system's robotic front-end [ ] must ensure that the subject is i) accurately and continuously followed by all aerial robots (UAVs), and ii) within the field of view (FOV) of the cameras of all robots. The back-end [ ] of the system estimates the 3D pose and shape of the subject, using the images and other data acquired by the front-end. The front-end poses a formation control problem for multiple MAVs, while the back-end requires an estimation method.
In existing solutions for outdoor MoCap systems, including ours [] [] [], the front and back end are developed independently. The formation control algorithms of the existing aerial MoCap front ends consider that their objective should be to center the person in every UAV's camera image and she/he should be within a threshold distance to each MAV. These assumptions are intuitive and important. Also, experimentally it has been shown that it leads to a good MoCap estimate. However, it remains sub-optimal without any feedback from the human pose estimation back-end of the MoCap system. This is because the estimated human pose is strongly dependent on the viewpoints of the UAVs.
Ziele und Aufgaben
In this project, our goal is to develop an end-to-end approach for human and animal motion capture - a MoCap system where the UAV-based front-end is completely driven by the back-end's accuracy.
To this end, our objectives are
- to develop a formation control method for multiple UAVs that is driven by the performance of the MoCap back end.
- to develop an integrated end-to-end method, where the UAV formation control policies are learned based on back-end's estimation accuracy, while at the same time the back-end improves its estimation accuracy using the images acquired by the front-end.
Methodolgie
In our most recent work [1] in this project, we introduce a deep reinforcement learning (RL) based multi-robot formation controller for the task of autonomous aerial human motion capture (MoCap). We focus on vision-based MoCap, where the objective is to estimate the trajectory of body pose and shape of a single moving person using multiple micro aerial vehicles. State-of-the-art solutions to this problem are based on classical control methods, which depend on hand-crafted system and observation models. Such models are difficult to derive and generalize across different systems. Moreover, the non-linearity and non-convexities of these models lead to sub-optimal controls. We formulate this problem as a sequential decision making task to achieve the vision-based motion capture objectives, and solve it using a deep neural network-based RL method. We leverage proximal policy optimization (PPO) to train a stochastic decentralized control policy for formation control. The neural network is trained in a parallelized setup in synthetic environments. We performed extensive simulation experiments to validate our approach. Finally, real-robot experiments demonstrate that our policies generalize to real world conditions.
Publikationen
[1] AirCapRL: Autonomous Aerial Human Motion Capture Using Deep Reinforcement Learning, Tallamraju, R., Saini, N., Bonetto, E., Pabst, M., Liu, Y. T., Black, M., Ahmad, A., IEEE Robotics and Automation Letters, IEEE Robotics and Automation Letters, 5(4):6678 - 6685, IEEE, October 2020, Also accepted and presented in the 2020 IEEE/RSJ International Conference on Intelligent Robots and Systems (IROS).
Team

Aamir Ahmad
Jun.-Prof. Dr.-Ing.Deputy Director (Research)

Eric Price
Dipl.-Inf.